Artificial intelligence has undergone a revolution because of deep learning, which allows machines to learn from large quantities of data and make sophisticated judgments. Deep Belief Networks (DBNs) stand out among the many deep learning architectures as a noteworthy invention. In order to capture both local and global dependencies, DBNs may learn hierarchical representations of data. By emphasizing its architecture, training techniques, and significant applications, Deep Belief Networks are examined for their relevance in the field of deep learning in this article.

Image Source|Google
Understanding
Deep Belief Networks:
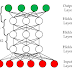
The
class of generative probabilistic models known as Deep Belief Networks is made
up of numerous layers of Restricted Boltzmann Machines (RBMs). Each RBM has a
bipartite graph made up of visible and hidden units linked by undirected
connections. Information may go from the input layer at the bottom to the
output layer at the top due to the layers' feed-forward connections. DBNs can
learn and reflect intricate hierarchical patterns in the data because to their
layered structure.
Training
Deep Belief Networks:
The training of DBNs typically involves a two-step process:
pretraining and fine-tuning.
Pretraining:
Fine-tuning: Following pretraining, the DBN is adjusted using supervised learning strategies such backpropagation. In order to reduce the prediction error, the network's parameters are fine-tuned using labeled data. The DBN may learn discriminative representations and enhance its performance for certain tasks, like classification or regression, thanks to this phase.
Advantages and Applications:
Feature Learning: The capacity of DBNs to automatically extract significant characteristics from unprocessed data is one of its main advantages. DBNs are exceptional in identifying and extracting relevant characteristics from complicated datasets because they learn hierarchical representations. This skill has applications in a variety of fields, including computer vision, voice recognition, natural language processing, and others where efficient feature learning is crucial.
Unsupervised
Learning:
Transfer Learning: For transfer learning, DBNs may use their accumulated hierarchical representations. A pretrained DBN's lower layers may be reused to do fine-tuning on a smaller labeled dataset, reducing the requirement for a lot of labeled data. In a number of applications, including image recognition and natural language processing, transfer learning using DBNs has shown significant gains.
Generative Modeling: DBNs are able to provide fresh samples that resemble the training set. For tasks like image synthesis, data augmentation, and creating new text sequences, this characteristic is helpful. DBNs may create innovative and varied instances that share features with the original dataset by sampling from the generative model.
Challenges and Future Directions:
Despite
their tremendous achievements, Deep Belief Networks still face difficulties.
Deep architecture training may be computationally demanding and require a large
amount of computing power. Training difficulties may also arise from gradients
that explode or vanish. Furthermore, because deep models' complicated
representations may be challenging to comprehend, interpretability of DBNs is
still a study topic of interest.
In
the near future, scholars will be working hard to solve these problems and
improve DBNs' capabilities. The future of DBNs in deep learning will continue
to be shaped by the development of more effective training algorithms, regularization
techniques, and interpretability methodologies. The discipline may also benefit
from investigating unique architectures and combining DBNs with other deep
learning models.
Conclusion:
In the realm of deep learning, Deep Belief Networks have become an effective tool that makes it possible to find hierarchical representations in large amounts of complicated data. Numerous fields have been transformed by their capacity to execute unsupervised learning, automatically learn features, and support transfer learning. The advancement of DBNs is expected to uncover even more possibilities for artificial intelligence as research and developments proceed, opening the door for advanced applications across several sectors and fields.