In
the area of artificial intelligence known as "natural language
processing," or NLP, the goal is to make computers capable of comprehending,
interpreting, and producing human language. Multilayer Perceptrons (MLPs), a
kind of artificial neural network, have shown their efficacy in a number of NLP
applications. This article will investigate the usage of MLPs in various NLP
tasks, such as text classification, sentiment analysis, named entity
identification, and machine translation.
 |
| Image Source|Google |
Understanding
MLPs:
The
information goes only in one way, from the input layer through the hidden
layers to the output layer, in a feedforward neural network called a multilayer
perceptron (MLP). MLPs are made up of numerous layers of synthetic perceptrons,
or artificial neurons. A perceptron is a fundamental computing structure that
processes weighted inputs, applies an activation function, and outputs the
results.
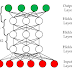
Structure
of MLPs:
Three
different layer types are present in MLPs: the input layer, one or more hidden
layers, and the output layer. The input layer is where the data is received,
and the output layer is where it is produced. As their name implies, the hidden
layers play a crucial part in identifying intricate patterns and connections in
the data even if they are not immediately related to the input or output.
Training
MLPs:
Forward
propagation and backpropagation are two essential techniques used in MLP
training. The input data is supplied into the network during forward
propagation, and the outputs are calculated by applying the weights and biases
unique to each link. To incorporate non-linearities and improve the model's
capacity to learn complicated connections, the activation function is applied
to each perceptron's output.
Following
forward propagation, the model's effectiveness is assessed using a loss
function, which measures the discrepancy between expected results and actual
results. To minimize this loss function is the goal of training.
Backpropagation is used to do this, and it involves calculating the gradients
of the loss function with respect to the model parameters (weights and biases).
The parameters are then updated using these gradients and optimization
approaches like gradient descent.
Activation
Functions:
MLPs
must have activation functions because they provide non-linearities into the
network. The sigmoid function, hyperbolic tangent (tanh) function, and
rectified linear unit (ReLU) are common activation functions used in MLPs. The
properties of each activation function affect the network's capacity to
represent various kinds of input and learn intricate relationships.
Text Classification with MLPs:
Text
classification is the process of classifying text materials into predetermined
groups or divisions. By using labeled text data for training, MLPs may be used
for this task. A numerical vector, such as the bag-of-words representation or
word embedding, is used to represent each document and is subsequently sent as
input to the MLP. Based on the patterns and connections it finds in the data,
the MLP learns to categorize the text. Tasks like spam detection, subject categorization,
and sentiment analysis may all be handled with this method.
Sentiment Analysis with MLPs:
Finding
the sentiment or opinion represented in a text is the goal of sentiment
analysis. By training on text data with sentiment annotations (such as
positive, negative, or neutral), MLPs may be used to create sentiment analysis
models. By obtaining the semantic and contextual details included in the text,
the MLP learns to recognize the sentiment. Monitoring social media, managing a
brand's reputation, and analyzing consumer comments are all areas where
sentiment analysis using MLPs has applicability.
Named
Entity Recognition (NER) with MLPs:
Named
Entity Recognition is the process of locating and categorizing named entities
in text, such as names of individuals, groups, places, and dates. By training
on annotated data that shows the borders and varieties of named entities, MLPs
may be used for NER tasks. In order to correctly detect and categorize named
items in the text, the MLP may be trained to recognize patterns and context clues.
Applications like information extraction, question answering, and knowledge
graph generation all depend on NER using MLPs.
Machine
Translation with MLPs:
The goal of machine translation is to convert text from one language to another automatically. By training on parallel corpora, which are collections of source texts and their translations, MLPs may be used for this purpose. In order to capture the syntactic and semantic connections between the languages, the MLP learns to map the representation of the source language to the representation of the target language. MLP-based machine translation has proved effective in a number of language pairings and is often employed in tasks like cross-lingual information retrieval and language localization.
Enhancing
MLPs in NLP:
Several
strategies may be used to improve MLPs' performance on NLP tasks. These consist
of:
Preprocessing:
Word Embeddings: To provide MLPs richer input representations, word embeddings like Word2Vec or GloVe may be used to capture the semantic links between words.
Dropout
and Regularization:
Ensemble
Methods:
Conclusion:
We are able to handle a variety of language-related tasks thanks to Multilayer Perceptrons (MLPs), which have shown to be effective tools in Natural Language Processing (NLP). MLPs have shown their effectiveness in comprehending and processing human language in a variety of contexts, including text categorization, sentiment analysis, named entity identification, and machine translation. We can improve the performance of MLP models in NLP applications by using strategies like as preprocessing, word embeddings, and regularization. In order to extract meaning and insights from text data and to pave the way for exciting new advancements in language interpretation and creation, MLPs will continue to be essential tools as NLP develops.



No comments:
Post a Comment